What happens when you open an app

Ever heard that mysterious 'zzzzzz' from your CPU when you launch a big app? Here’s what's going on behind it.

We’ve all been there——tapping away on our screens to open apps that promise to make our lives easier. Behind that single tap or click lies a complex symphony of operations. From loading instructions into memory to allocating resources, your CPU, memory, and the Operating System spring into action. But have you ever paused to wonder what’s really happening behind the scenes when you launch those applications? Buckle up to dive into the fascinating process that brings your app to life, because the Process is more fascinating than you think!
First and foremost, what really is an application? At its core, an application is simply code written in a specific programming language, tailored to a particular platform like iOS or Android. This code is compiled into an executable file, optimized to run on that platform’s unique CPU architecture.
When you open the application, the Operating System copies the machine code present in the executable file of your program to memory and remains until it completes its job. This creates a Process for every application that you have opened. Now the CPU fetches this machine code from the process, and executes the instructions. This is the tl;dr version of this blog.
But what exactly is a process? It is nothing but a part of memory reserved for all the data required for your application to run. Process is primarily a program in action. A single program can have multiple processes. Each and every process gets a minimum and maximum physical address in memory. So when you open an application, the OS spins up a process that reserves memory for your application to run. Process is the most complex part of the running an application. Let's deep dive into what actually happens in a process.
Glossary:
Pointer: Anything that stores the memory address of another variable or object, providing indirect access to data in memory.
Register: A small, fast storage location inside the CPU used to hold data that the processor is currently working with.
Process
The process consists of multiple sections. A section in a process is nothing but a logical separation of different kinds of data, based on their usage and memory size.

Text Section
The fundamental section in a process is the text section which holds the compiled machine code. Fundamentally, to execute a program, it needs to be broken down into instructions that can directly be executed by the CPU. The machine code is exactly the instructions that the CPU can understand, that's why it is stored in this separate section for easy access. No process can be created without a text section as it holds the machine-readable code to be executed, and if there is no code, then there is nothing to execute. So as soon as you open the app, the machine code of the app is copied to the Text Section.

The actual instructions are executed by the CPU. The CPU fetches the instructions and executes them one by one. There are two components, Instruction Pointer(IP) and Instruction Register(IR), which are used to manage the execution of these instructions.
Instruction Pointer
The Instruction Pointer, also known as the Program Counter, is a special type of register and one of the crucial components of the CPU. The job of an IP is to hold the memory address of the next instruction to be executed. Its primary function is to ensure that the CPU fetches instructions from the correct location in memory so that it can be executed in the correct sequence.
After fetching the instruction, the IP is typically incremented to point to the subsequent instruction unless control flow instructions like jump(loops), call(function calls), or branch(conditional statements) alter the sequence.
Instruction Register
Instruction Register is the special type of register that actually stores the instruction that has been fetched from memory and is currently being executed. The CPU decodes the instruction in the Instruction Register to determine what operation to perform and on which operands.
The content of the Instruction Register is interpreted by the control unit, which then orchestrates the necessary actions to carry out the instruction.

Stack
Stack is the section used to store and manage function calls, along with the parameters passed to those functions. Every app will have an entry point where the execution starts from, this is typically a main function. So the process creates a frame for this function in the Stack and stores all the local variables, and function parameters that don't require large memory, e.g., integers, characters, strings within the Stack.
In most systems, the Stack grows downward—from high memory addresses to low. This design helps keep it separate from the Heap, which typically grows upward. Stack space is limited and allocated when the process starts, ensuring efficient memory management within a fixed address range.
Apps are huge and their code is impossible to bind in a single main function. Hence, every app generally contains anywhere from 10's to 100's of functions. When the main function calls another function, the process creates a new frame for this function similar to the main function. Now there are two frames in the Stack section. If this new second function has a call to another third function, a new frame will be created for that function as well. So the more nested functions we have, the more Stack frames we will have in the process, and might end up consuming all the limited memory assigned for a Stack. This is called Stack Overflow. It is also the reason why recursion is very tricky and considered a dangerous practice if not done correctly.

Consider this program:
#include <stdio.h>
int add(int a, int b);
int multiply(int a, int b);
int subtract(int a, int b);
int main() {
int x = 10, y = 5, z = 2;
// Nested function call: first multiply, then subtract, then add
int result = add(subtract(multiply(x, y), z), 3);
printf("The result is: %d\n", result);
return 0;
}
int add(int a, int b) {
return a + b;
}
int multiply(int a, int b) {
return a * b;
}
int subtract(int a, int b) {
return a - b;
}
The first Stack frame for this process will be for the main function. This frame will contain the variables x, y, z, and result. The value of the variable result will be the return value of the add function. Now the new frame for the add function will be created which will have the variables a, and b provided as the function parameters. But as you see the first parameter for that function will be the return value of the subtract function, in turn, whose first parameter is the return value of the multiply function.
This is what our Stack looks like, consisting of four frames, that is, main, add, subtract, and multiply.
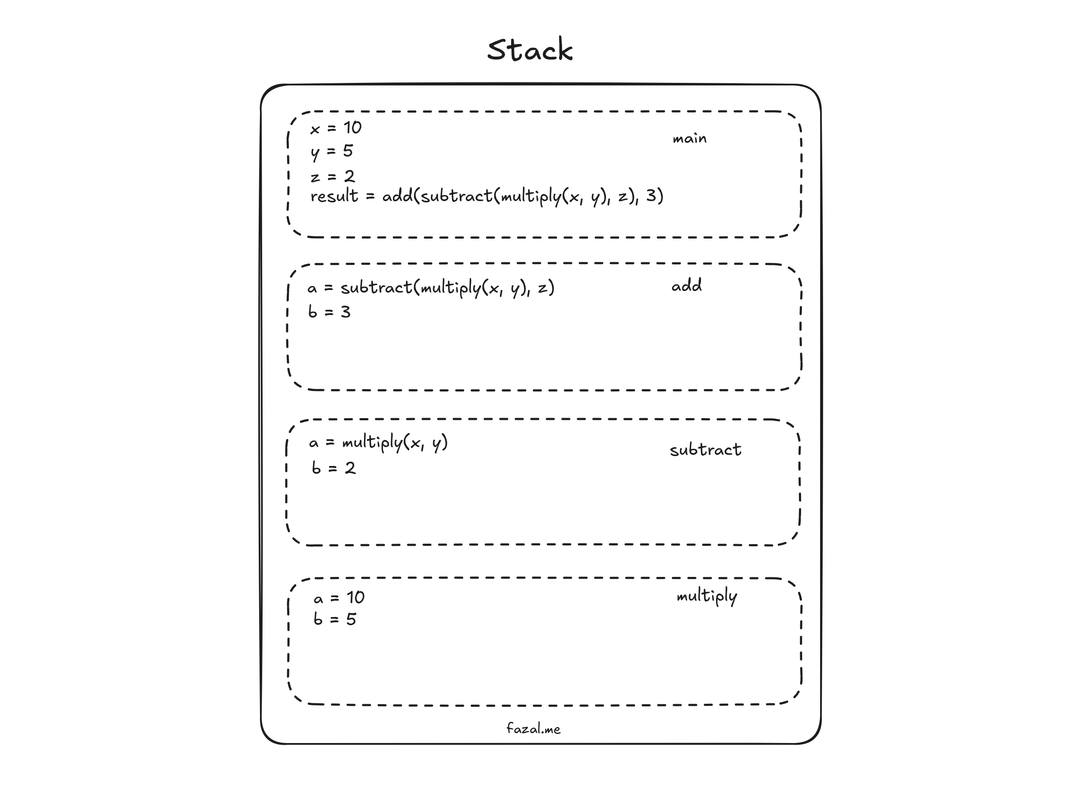
Once the multiply function is done, it returns the value to the subtract function, which then computes and returns the value to the add function. Ultimately, the add function will compute and return the value to the result variable in the main function.
Stack becomes complex and gets hard to manage as it grows. That is why two CPU registers, Stack Pointer(SP) and Base Pointer(BP), are used to manage the Stack.
Stack Pointer
The Stack Pointer points to the top of the currently active Stack frame, which is the location where the most recent item was pushed onto the Stack. It is used to keep track of the top of the Stack as it grows and shrinks during function calls and returns.
Base Pointer
The Base Pointer, also known as Frame Pointer, points to the base of the currently active Stack frame, which represents the starting point of the Stack space allocated for the current function. It serves as a stable reference point for accessing function parameters and local variables.
But wait a minute? How does a function, once it has done its job and is ready to be deallocated from the Stack, know where it should return the value? Moreover, where should SP and BP be now in the preceding Stack frame?
Stack frames will also store the return address and BP of the function it was called from. Once the function has done its job, it pops all local variables, function parameters, and then the old BP, which will restore the BP to the preceding Stack frame. Then the return value is returned to the address stored in the return address. SP doeesn't need explicit management as it is automatically adjusted by popping values (the old BP and return address) off the Stack.

Heap
The Heap section is for storing data that requires large amounts of memory, generally those that require dynamic memory allocation. Dynamic Memory allocation is the process of allocating and deallocating memory during runtime as needed. Any data type that requires dynamic memory allocation goes straight to the Heap. For example, a linked list can grow dynamically, hence it is stored in the Heap.
Even an array in C language will be stored in the Heap if it is created with malloc, which is used for dynamic memory allocation. The best thing about Heap is you get as much memory as physically available. But the downside is you need to explicitly manage the allocation and deallocation of the objects. If the allocated memory is not explicitly deallocated, it would lead to the most dreading thing in programming, memory leak. You forget one free call and——BOOM——your application is no longer memory safe.
#include <stdio.h>
#include <stdlib.h> // for malloc and free
int main() {
int *ptr;
// Allocate memory for an integer in the Heap
ptr = (int *)malloc(sizeof(int)); // dynamically allocate memory for one integer
// Check if the memory allocation was successful
if (ptr == NULL) {
return 1; // exit the program if malloc fails
}
// Assign value to the allocated memory
*ptr = 42;
// Free the allocated memory
free(ptr);
return 0;
}
Here is what this program's Stack and Heap looks like when it is in process.
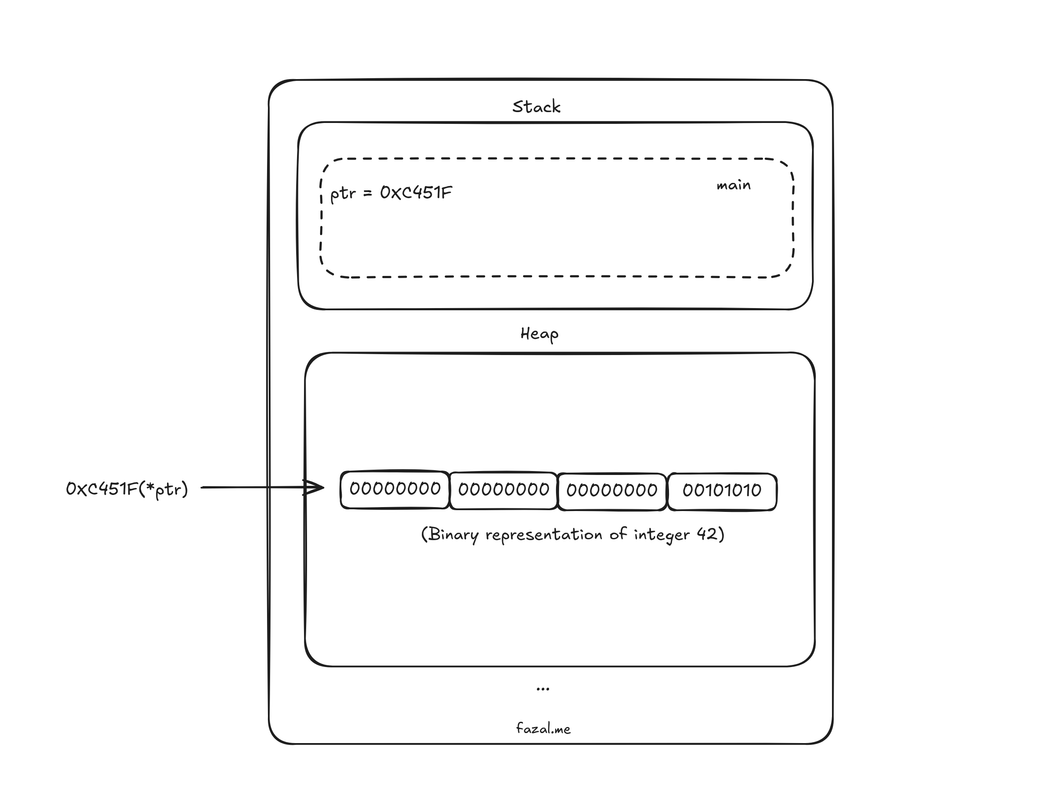
When you call the (int *)malloc(sizeof(int)) to reserve memory for storing an integer, it returns you any random memory address available to store an integer, which will always be in Heap. Then, we store the integer 42 in the given location by using asterisk *ptr = 42, which specifies to store the value in the address that the variable points to, not in the actual variable. In comparison, if you would have done int x = 42, the value would be stored in the Stack itself. Ultimately, if the memory used for storing the integer is not deallocated using free(ptr), the integer 42 will always be present in that address during the process and cannot be used for storing any other thing. Whereas in Stack, all the memory used for storing local variables and function parameters is deallocated as soon as the function returns and the Stack frame is removed.
Another important thing to keep in mind while using dynamically allocated objects or pointers is to make sure that they are deallocated or freed only by the function that it was created by. If you pass a pointer as parameter to a another function, and if that function frees that pointer and returns, the function that called this function might need access to that pointer's value, but it will either get garbage value or null. Such pointers are aptly named Dangling Pointers. Further, if you try to free an already freed pointer, it will crash the program.
When you deallocate something from memory, where do you put the data that has been removed? Deallocation doesn't mean explicitly removing something from the memory. It just informs the Operating System that the data stored at this memory address is no longer required, hence the OS can utilize that space for allocating any other data.
However, the explicit allocation and deallocation of memory is only required for ancient languages like C/C++. Modern programming languages have built Garbage Collections to manage and overcome memory leaks. They have reduced so much overhead task of managing memory, which helps developers focus on actually solving the logical problems. Its working is straightforward. When you create an instance of an object or a data type that is stored in the Heap, the Garbage Collector maintains the number of references to that instance. As the number of references goes to zero, the Garbage Collector frees the object and that memory is deallocated. Recently, even the US Government has advised using memory-safe languages, which contain Garbage Collections, like Java for building any software.
Since the memory in the Heap is dynamically allocated, there is no guarantee that two variables, that require dynamic memory allocation, initialized one after the other are stored next to each other. They can be stored wherever there is memory available. This makes read operations slow for the data stored in the Heap.
Golang has the concept of escape analysis where it puts dyanamically allocated objects in the Stack rather than the Heap if it is not used anywhere apart from that function.
Data Section
All the Global Variables and Static Variables, which are local to any function or file, sit in the Data Section. Things in the Data Section have a lifespan the same as that of the process. The reason why these variables get a separate section is that they are supposed to be required for the entire duration of the program. Hence, it is optimized to put it in a separate section as they are fixed in size and initialized only once, which also helps in accessing without passing it as parameters or maintaining a pointer.
Global variables and Static variables are generally marked as immutable. Modifying them causes unintended consequences, hence it is labeled as bad practice. You want to keep their value the same for the entire duration of the program.
But in case there is a need to modify them, here is what you need to keep in mind about modifying things in the Data Section. If any function modifies the Global variable anywhere, it will immediately change everywhere it is being referred. If a function modifies a local Static variable and then exits, the value of that Static variable will remain the same as it was when last modified. If the function is called again, the Static variable will retain its previous value. This is because they are initialized only once, that is during compile time, and not on every function call. The primary use of Static variables within a function is to retain their value across multiple calls to that function, even though the function’s Stack frame is removed after each call.
#include <stdio.h>
void incrementCounter() {
static int counter = 0; // Static variable initialized only once
counter++; // Retains its value across function calls
printf("Counter: %d\n", counter);
}
int main() {
incrementCounter(); // Output: Counter: 1
incrementCounter(); // Output: Counter: 2
incrementCounter(); // Output: Counter: 3
return 0;
}
Here is a catch in memory management I bet you didn't know. If you have to implement a Singleton pattern, having only one instance of a Class, you need to declare it as a static variable. As all objects are dynamically allocated, it is usually assumed that they should be present in the Heap section of the process. But here the catch is that the instance is declared as static, so is it stored in the Heap or Data Section? I think the answer depends on how you actually implement the class, the static variable, and the nuances of the language you are working with.
To summarize the process part, the machine code is the most important component of the process which is stored in the Text Section. The rest of the sections are split based on the type of data and its usage for easy access. If the data is required to execute the instruction, the CPU fetches it from the appropriate section.
Interpreted vs Compiled Programs
Whatever we have discussed so far was in the context of compiled languages like C and C++, which produce an executable file. Interpreted languages like Python don't generate any executable files. The reason is computers don't understand Python. The way we execute Python code is that we first run the interpreter, and pass the script as argument.
python main.py
So what goes into the Text Section is the Python interpreter, not the source code written by you. The source code probably sits in the Heap Section. This is the reason why compiled languages are faster than interpreted languages.
Execution
Once the program is loaded in memory, that is, it is now in process, the CPU starts fetching instructions from the Text Section to execute. When any instruction requires data to execute, the CPU fetches it from any of the sections based on their location.
But it not only fetches that single piece of data, it fetches a fixed number of bytes surrounding the location of the data required by the CPU to execute the instruction. This is because of Cache Burst. When any data required for execution is fetched by the CPU from memory, it also fetches the data surrounding the required data and caches it. It helps the CPU save another fetch call if the data required for executing the next instructions is already cached in the CPU. Most modern CPUs cache this data among multiple layers inside them.

-
L1: Closest to the CPU core. Generally split into
instruction cache (L1i)anddata cache (L1d), allowing the CPU to fetch instructions and data in parallel. Small, typically 32KB to 128KB per core. -
L2: Larger than L1 but slower and still dedicated to each CPU core. Spans 256KB to 1MB per core in size.
-
L3: Shared among all cores of a CPU. Larger but slower compared to L1 and L2. Acts as a last level of cache before accessing the much slower main memory (RAM). Size extends from 2MB to 64MB, depending on the CPU architecture.
This might seem overengineered, but on a modern general-purpose machine, the numbers for the time taken for accessing something stored in the CPU against fetching it from memory speaks for themselves:
| Location | Time taken to fetch |
|---|---|
| Register | 1ns |
| L1 Cache | 2ns |
| L2 Cache | 7ns |
| L3 Cache | 15ns |
| Memory | 100ns |
One key to speeding up your program's execution is ensuring that data in memory is stored as closely together as possible. This proximity improves cache efficiency and reduces memory access time. That’s why, as I mentioned earlier, the Heap is often considered slower—it allows dynamic memory allocation but at the cost of more scattered data. The Stack, on the other hand, is faster because of its tightly organized structure, but it’s also limited in size. Like everything in Computer Science, it’s a delicate balance of trade-offs between speed and flexibility.

As software engineers, we often write code without fully considering the deep, underlying mechanics. However, understanding these implications can dramatically elevate your decision-making and craftsmanship. I hope that these insights empower you to write more efficient, thoughtful programs moving forward.
Thank you for reading this till the end. Please consider sharing this if you think it will help other people. Connect with me on LinkedIn for more.
Disclaimer: Any public media used on this blog are the property of their respective owners and are used in accordance with the fair use provisions outlined in 17 U.S. Code § 107. This section allows for limited use of copyrighted material without permission for purposes such as commentary, criticism, news reporting, education, and research.